java中为了方便操作多个对象,需要将它们存放到一个容器中,这个容器就是集合类
集合类提供了丰富的api来简化我们的编程,对于多个元素我们可能会有不同的需求,为此提供了多种集合类,底层数据结构包括数组,链表,队列,栈,哈希表等,所有我们就可以根据不同的需求选择合理的集合类进行解决
集合类作为容器类可以存储任何类型的数据(存储对象的引用),无法存储基础类型,对于基础类型需要将其包装为包装类在进行存储,底层实现使用数组的集合类支持动态扩容
java中的集合类都在java.util包中,可分为Collection集合和Map映射两种
Collection
实现Collection接口的集合类主要包括:List,Set,Queue

List集合
有序列表,可以存储重复数据
ArrayList
那基于数组实现,所以随机访问快,增删慢(需要移动数据),线程不安全

ArrayList实现过程不难
我们看一下添加元素的时候如何进行扩容
public boolean add(E e) {
//扩容方法
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
//如果数组是空的,使用默认初始容量 10
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
//扩容
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
// 新的数组容量扩充为原来的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// 调用System.arraycopy方法进行扩容
elementData = Arrays.copyOf(elementData, newCapacity);
}默认扩容的大小为原来的1.5倍
删除方法
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}删除数据的时候,如果删除的数据后面还有数据需要在删除数据后将删除数据后面的数据往前移动
扩容和新增删除需要移动数组,底层使用方法都是System.arraycopy()
LinkedList
基于双向链表实现,所以增删快,查询慢,线程不安全

LinkedList中维护了双向链表的头节点和尾节点,让我们看一下节点的结构Node

Node的属性有当前节点的值,下一个节点和前一个节点,LinkedList整个结构非常清晰
添加元素
public boolean add(E e) {
linkLast(e);
return true;
}
/**
* Links e as last element.
*/
void linkLast(E e) {
// 将最后一个元素赋给变量 l
final Node<E> l = last;
// 构造新的节点 newNode
final Node<E> newNode = new Node<>(l, e, null);
// 将newNode放到队列尾部
last = newNode;
// 如果原队列尾部的节点为null
if (l == null)
// 新构造的节点为队列头节点
first = newNode;
else
// 不为空则将 l 的next节点指向 newNode
l.next = newNode;
// 队列数量加1
size++;
// 操作次数加1
modCount++;
} 代码逻辑清晰,新添加的元素加到队列的尾部
删除元素
public E remove() {
return removeFirst();
}
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
/**
* Unlinks non-null first node f.
*/
private E unlinkFirst(Node<E> f) {
// 获取当前节点的元素及下一个节点
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
// 将下一个元素设置为队列首元素
first = next;
if (next == null)
// 队列为空队列
last = null;
else
// 队列首元素的前一个节点引用置为null
next.prev = null;
size--;
modCount++;
return element;
}删除的操作逻辑也比较清晰,删除队列的头节点
还有一些其他方法,代码逻辑也比较清晰,可自行查看
LinkedList实现了Deque接口,而Deque接口继承自Queue接口,因此LinkedList也提供了对于队列的实现,能实现队列肯定也能实现栈
Vector
Vector也是数组实现,线程安全,性能较ArrayList差
添加元素
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
private void ensureCapacityHelper(int minCapacity) {
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
// 扩容为原来的一倍
int newCapacity = oldCapacity + ((capacityIncrement > 0) ? capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}看源码的时候可以看到,Vector的方法都使用synchronized进行修饰,所以线程安全,但是加锁就意味着性能损耗,与ArrayList不同的是扩容时容量会扩为原来的一倍
Stack
栈:保证数据先进后出,简称FILO原则
Stack继承Vector类,实现了栈操作,看源码可以看到它调用的都是Vector的方法,这个类也基本不怎么会用,如果想要实现一个栈可以用实现了Dueue接口的子类,比如LinkedList,后面会讲到
Queue队列
队列一种特殊的线性表,遵循的原则就是“先入先出”,简称FIFO
先看一下Queue接口定义的方法

- add:添加元素到队列尾部,如果操作失败会报异常
- remove:获取队列首部第一个元素,并从队列中删除,如果操作失败会报异常
- element:获取队列首部第一个元素,单不从队列中删除,如果操作失败会报异常
- offer:添加一个元素到队列尾部,操作失败不会报异常
- poll:获取队列首部第一个元素,并从队列中删除,操作失败不会报异常
- peek:获取队列首部第一个元素,单不从队列中删除,操作失败不会报异常
队列新元素都插入队列的末尾,移除元素都移除队列的头部
队列
Queue接口的子类按不同维度可以分为两种,一种是阻塞还是非阻塞队列,一种是单端还是双端队列
阻塞与非阻塞主要看是否实现了BlockingQueue接口或BlockingDeque接口,实现了的是阻塞队列,比如:ArrayBlockingQueue,LinkedBlockingQueue,LinkedBlockingDeque
未实现的是非阻塞队列,比如:ArrayDeque,LinkedList,PriorityQueue
*Deque *接口是Queue接口的子接口,代表一个双端队列,比如前面学过的LinkedList
Deque 接口提供的方法:
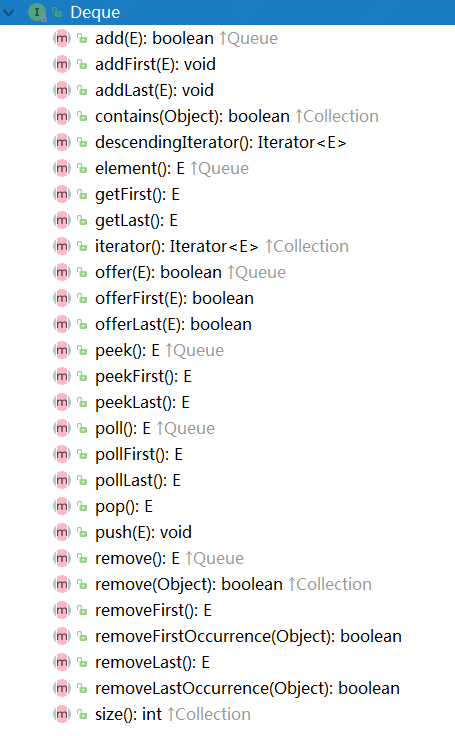
方法的作用可以根据方法名看出来,对比queue接口提供的方法,queue接口只提供了在队列尾部添加元素,获取移除队列首部的元素,而Deque接口实现了对于队列双端的添加删除操作
Deque 接口的实现类不仅可以当做队列,也可以实现栈,比如使用入栈方法:offerFirst(E e); 出栈方法:E peekFirst()
阻塞队列与非阻塞队列实现区别
阻塞接口提供的方法:
看下BlockingQueue接口

阻塞接口中的阻塞方法
- put : 用来向队尾存入元素,如果队列满,则等待;
- take: 用来从队首取元素,如果队列为空,则等待;
- offer(E e,long timeout, TimeUnit unit) : 用来向队尾存入元素,如果队列满,则等待一定的时间,当时间期限达到时,如果还没有插入成功,则返回false;否则返回true;
- poll(long timeout, TimeUnit unit) : 用来从队首取元素,如果队列空,则等待一定的时间,当时间期限达到时,如果取到,则返回null;否则返回取得的元素;
以ArrayBlockingQueue为例:

阻塞队列与非阻塞队列的实现区别就是是否使用了ReentrantLock和Condition
添加元素:put(E e) 方法
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
// 队列满了
while (count == items.length)
//进入等待状态
notFull.await();
enqueue(e);
} finally {
lock.unlock();
}
}当数组里的数量等于数组的长度,也就是队列满了,执行notFull.await();进行阻塞,直到当前线程被中断或者其他线程调用了改notFull这个Condition的signal()方法或signalAll()方法
删除元素时阻塞的原理也是一样的,调用notEmpty.await()进行阻塞,唤醒条件也是一样的
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0)
notEmpty.await();
return dequeue();
} finally {
lock.unlock();
}
}所以,阻塞队列的实现原理就是用ReentrantLock和Condition实现的
Set集合
无序集合,不允许存放重复的元素
HashSet
无序集合,允许元素为null

HashSet底层使用HashMap实现,采用HashCode算法来存取集合中的元素,因此具有比较好的读取和查找性能
对于添加的元素key为要添加值,value为一个static final object对象,对于添加重复的值,以前的值会被覆盖
对于HashSet的迭代,只需要调用的是HashMap的keySet()来获取到map中的key值的Set集合进行迭代
public Iterator<E> iterator() {
return map.keySet().iterator();
}LinkedHashSet
HashSet的子类,底层实现是LinkedHashMap,利用双向链表保证了元素的有序性
public LinkedHashSet() {
super(16, .75f, true);
}
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}TreeSet
TreeSet实现了SortedSet接口,所以这个是一种有序的Set集合,查看源码发现底层实现是用的TreeMap,而TreeMap使用红黑树实现
public TreeSet() {
this(new TreeMap<E,Object>());
}使用TreeSet时需要注意,添加到TreeSet中的对象需要实现Comparable重写compareTo接口,或者自定义一个类实现Comparator接口重写compare方法,否则会报异常(讲TreeMap时会详解)

Set集合的实现基本都是复用了Map的实现,使用map中的key存储set中的数据
Map
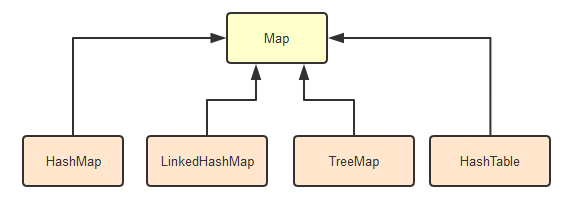
Map,散列表,它存储的内容是键值对映射(key-value),先上个图,介绍下要讲的四种map实现
HashMap
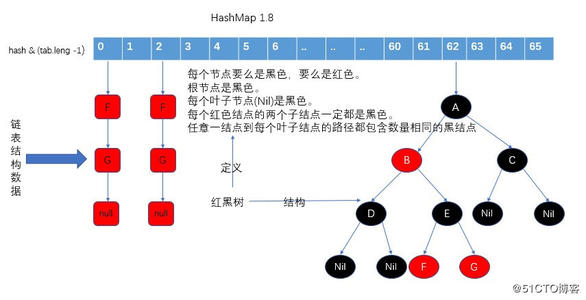
最常用的当属HashMap,jdk1.7时底层实现的数据结构是散列表(数组+链表),jdk1.8时底层数据结构为数组+链表/红黑树,1.8加入红黑树是为了解决链表过长所带来的性能消耗
结构如下:网上找的图片
常用的属性:
/**
* 默认容量
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* 默认的平衡因子
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 由链表转为红黑树的阈值
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* 由红黑树转为链表的阈值
*/
static final int UNTREEIFY_THRESHOLD = 6;
/*
* 负载因子
*/
final float loadFactor;
/**
* 是否扩容的阈值 threshold = 容量 * loadFactor
*/
int threshold;
/**
* 数组,桶,槽位 存储该位置上的链表的头节点
*/
transient Node<K,V>[] table;我们知道Hashmap中的数组存储的是链表的头节点的引用,那我们看下节点的结构:
为链表时节点的结构:

包括hash值,key,value,以及指向下一个节点的引用
为红黑树时节点的结构:

包括父节点,左右节点,和节点颜色
对元素进行操作时,比如添加操作,会通过key的hash值找对应的数组下标位置,如果该位置对应的链表或红黑树为空,则该元素为头节点,如果有元素,则调用equals方法进行比较,如果相等就进行覆盖,如果不相等就进行添加
LinkedHashMap
LinkedHashMap继承自HashMap,与hashMap相比最大的区别在于LinkedHashMap存储的数据是有序的
在LinkedHashMap内部维护了一个双端队列,保证添加的数据的顺序性

LinkedHashMap重写了HashMap提供的模板方法来对链表进行维护
在HashMap中的put操作

其中afterNodeAccess(e)就是暴露给子类的模板方法,此外还有:

TreeMap
TreeMap是SortedMap接口的实现类
TreeMap 是一个有序的key-value集合,通过红黑树实现,每个key-value作为红黑树的一个节点

Comparator,在讲TreeSet的时候说过,TreeSet支持两种排序方式,自然排序和定制排序
自然排序:key需要实现Comparable接口重写compareTo接口,而且所有的key应该是同一个类的对象,否则会抛出异常
定制排序:自定义一个类实现Comparator接口重写compare方法,这个类负责对TreeMap中的所有key进行排序,否则会抛出异常
我们看下红黑树的节点:

包括:key,value信息,父节点,左右节点和节点颜色
在HashMap中判断节点是否相等时,是先比较key的hash值,如果相等在用equals进行比较
而在TreeMap中是两个key通过compareTo()方法如果返回值是0,则两个key相等
HashTable
Hashtable,散列表,存储的也是键值对,继承自Dictionary抽象类,其提供的方法都是同步的,key和value都不可以为null,数据结构为散列表(数组+链表)

实现原理与HashMap相同,使用Synchronize实现线程安全,看了源码,扩容时容量为newCapacity = (oldCapacity << 1) + 1; 感兴趣的可以自行查看一下源码
终于写完了,Java中常用的集合类都有讲到,不过有些地方只是一概而过,感兴趣的可自行看一下源码实现